论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
介绍
在这篇论文中,作者同时使用低秩核和稀疏核(low-rank and sparse kernel)来组成一个密集kernel。基于ICGV2的基础上,作者提出了ICGV3。
近几年,卷积网络在计算机视觉上的有效性已经得到了验证。目前卷积网络的发展主要有两个方向:一是朝着更深的方向发展,在网络各层之间增加skip connection,使得训练更深的网络成为可能;二是简化卷积网络的结构,消除里面的冗余性,增加更多的有效计算,同时减小参数和总计算的数量。
简化网络结构的方法主要有:
采用低精确度的核
该方法将卷积核内的权重值由浮点型数据,转变为采用更少bit位表示的数据类型,如采用二进制表示权重,使得权重值仅为-1或+1,这样在网络计算时,就减少了存储空间的使用。 采用稀疏或低秩核 稀疏核主要是通过采用L1或L2正则化来增加核的稀疏性,稀疏核中只有通过将部分权重值设为0,从而减少计算量。
采用稀疏或低秩核 稀疏核主要是通过采用L1或L2正则化来增加核的稀疏性,稀疏核中只有通过将部分权重值设为0,从而减少计算量。 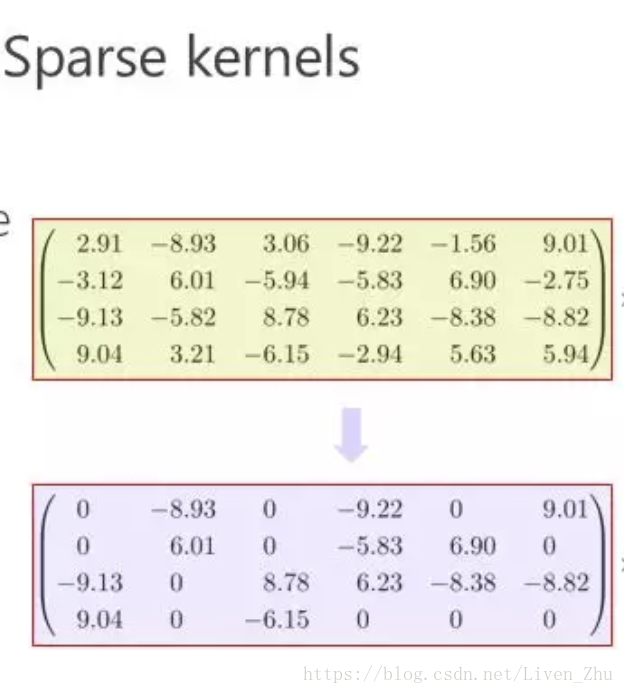 低秩卷积核主要是通过将一个大的卷积核分解成小的卷积核相乘的形式,如一个二维卷积核的大小为100*100,可以将其分解为100*10和10*100两个卷积核相乘的形式。
低秩卷积核主要是通过将一个大的卷积核分解成小的卷积核相乘的形式,如一个二维卷积核的大小为100*100,可以将其分解为100*10和10*100两个卷积核相乘的形式。 
Depthwise卷积与Pointwise卷积
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如。
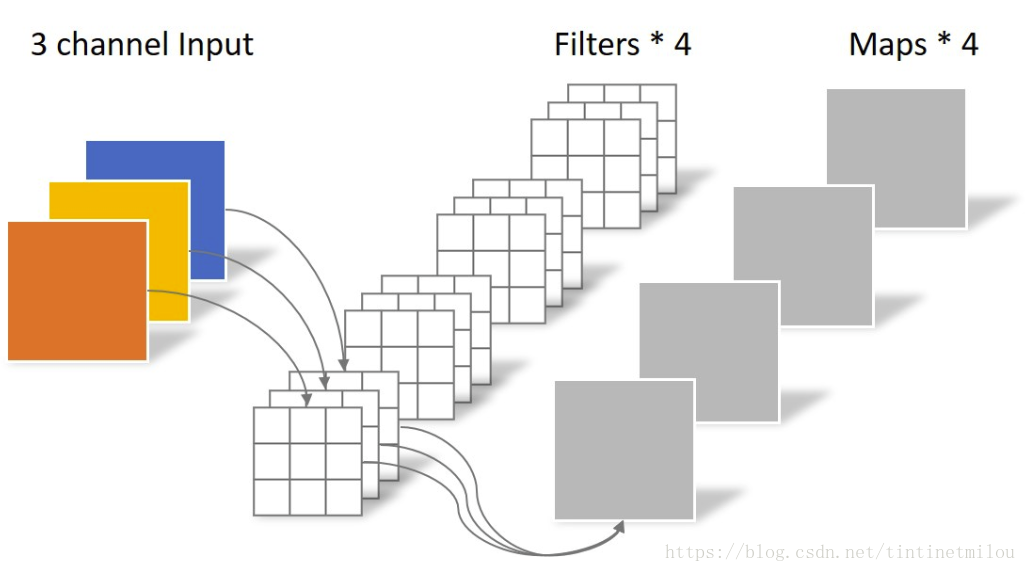
常规卷积操作
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
Depthwise Separable Convolution
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。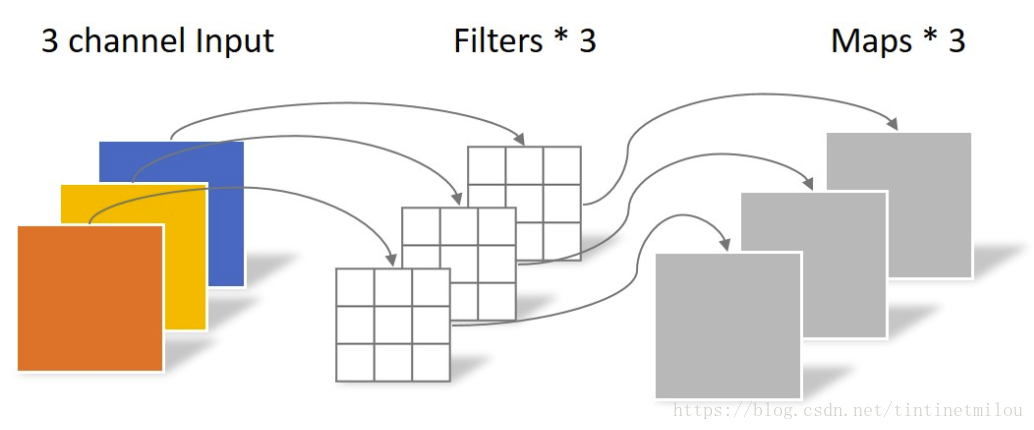 Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
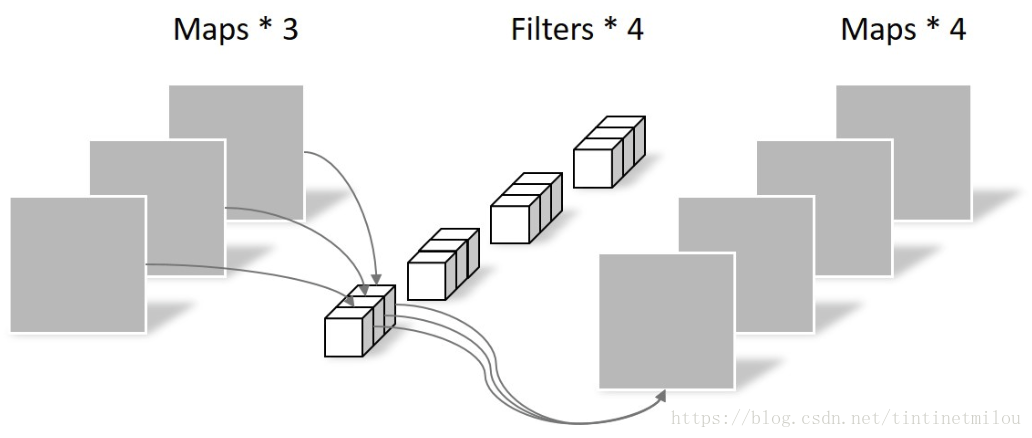
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。 Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
本文参考尹国冰的博客—